ヘンリーで SRE をやっている ![]() id:nabeop です。最近の仕事のテーマはサービスの可観測性の向上と信頼性の計測です。
id:nabeop です。最近の仕事のテーマはサービスの可観測性の向上と信頼性の計測です。
最近では可観測性の文脈では OpenTelemetry が話題に上がると思いますが、ヘンリーでも OpenTelemetry を導入してテレメトリデータを収集して、各種バックエンドに転送しています。分散トレース周りの話題については、以下のエントリがあります。
ヘンリーではマイクロサービスからのテレメトリデータは Cloud Run で構築した OpenTelemetry Collector で集約し、otelcol のパイプライン中で必要な処理を実施し、バックエンドに転送するアプローチを採用しています。
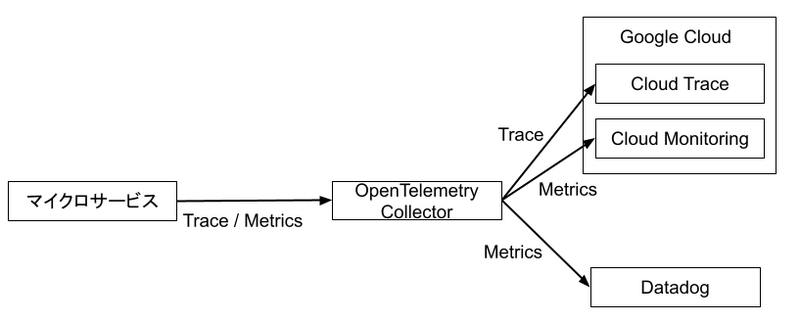
現在は監視基盤の移行期なので、メトリクスが Google Cloud と Datadog の両方に転送されていますが、将来的には Datadog に一本化される見込みです。
今回のエントリでは OpenTelemetry Collector 自体の可観測性をどのように確保しているかについて紹介します。
OpenTemetry Collector の内部メトリクスを Prometheus 形式でエクスポートする
OpenTelemetry Collector のモニタリングについては以下のドキュメントが参考になります。
また、OpenTelemetry Collector 自体の可観測性の考え方についてはこのようなドキュメントがあります。このドキュメントでは実験的なアプローチとして OTLP でテレメトリデータを外部に転送するアプローチが紹介されています。今回は以下の理由から OTLP によるエクスポートを選択せず、Prometheus 方式で OpenTelemetry Collector の内部情報をエクスポートするアプローチを採用しました。
- OTLP でのエクスポートは実験的という扱いである
- 前述のモニタリング方法のメトリクスが Prometheus 形式で記述されている
したがって、OpenTelemetry Collector の内部のメトリクスを Cloud Monitoring と Datadog の双方に転送する OpenTelemetry Collector の設定は以下のようになりました。
receivers: prometheus: config: scrape_configs: - job_name: otel-collector scrape_interval: 30s static_configs: - targets: ['0.0.0.0:8888'] processors: batch: send_batch_size: 8192 timeout: 15s transform/gcp: metric_statements: - context: datapoint statements: - set(attributes["exported_service_name"], attributes["service_name"]) - delete_key(attributes, "service_name") - set(attributes["exported_service_namespace"], attributes["service_namespace"]) - delete_key(attributes, "service_namespace") - set(attributes["exported_service_instance_id"], attributes["service_instance_id"]) - delete_key(attributes, "service_instance_id") - set(attributes["exported_instrumentation_source"], attributes["instrumentation_source"]) - delete_key(attributes, "instrumentation_source") - set(attributes["exported_instrumentation_version"], attributes["instrumentation_version"]) - delete_key(attributes, "instrumentation_version") exporters: googlecloud: datadog: api: site: datadoghq.com key: ${env:DD_API_KEY} service: telemetry: metrics: address: ":8888" pipelines: metrics/promethus-for-datadog: receivers: [prometheus] processors: [batch] exporters: [datadog] metrics/promethus-for-gcp: receivers: [prometheus] processors: [batch, transform/gcp] exporters: [googlecloud]
service の telemetry.metrics によって OpenTelemetry Collector の内部メトリクスを Prometheus 形式で 0.0.0.0:8888/tcp でエクスポートして、prometheus レシーバーで Prometheus 形式のテレメトリデータを収集しています。
また、Cloud Monitoring にメトリクスを転送しようとした際に「Duplicate label Key eccountered」というエラーが発生し、メトリクスデータの転送に失敗していたので、google exporter の README.md の記述を参考に transform プロセッサーで transform/gcp としてメトリクスの属性を exported_ プレフィックスをつけた属性名に置き換えています。
このようなパイプライによって、Datadog と Google Cloud の Cloud Monitoring の両方で OpenTemetry Collector の内部メトリクスが他のマイクロサービスと同様に観測できるようになりました。
今後の課題
今回のアプローチでは Prometheus 形式でエクスポートしていますが、前述の OpenTelemetry Collector の Observability のドキュメントでは実験的という立ち位置ですが、将来的に OTLP 形式に置き換わることが示唆されています。将来的に OTLP 形式が推奨となり、Prometheus 形式でのエクスポートが非推奨となった場合、メトリクス名もドット区切りの OTLP 形式に置き換わることが予想されるので、メトリクスデータの連続性が失われることが課題になりそうと思っています。
また、OpenTelemetry Collector のモニタリングのドキュメントでは転送時にエラーになった場合は otelcol_processor_dropped_spans や otelcol_processor_dropped_metric_points がカウントアップされるとありましたが、我々の環境ではこれらのメトリクスは生成されていませんでした。今は代替として otelcol_exporter_send_failed_spans や otelcol_exporter_send_failed_metric_points を監視するようにしています。
We are hiring!!
ヘンリーでは各種エンジニア職を積極的に採用しています。Henry が扱っている医療ドメインは複雑ですが、社会的にもやりがいがある領域だと思っています。複雑な仕組みを実装しているアプリケーションには可観測性は重要な要素です。一緒にシステムの可観測性を向上しつつ、複雑な領域の問題を解決してみませんか?