ヘンリーのオンボーディングでは「初日」「最初の1週間」「最初の1ヶ月」の3つの粒度でヘンリーが開発しているクラウド型電子カルテ・レセコンシステムの Henry の概要や開発で必要となってくるドメイン知識だけでなく、ヘンリーの文化やプロダクトの機能などを効率よくキャッチアップできるようにタスクが組まれていてとても助かりました。実際にヘンリーに入るまではレセコン*1という言葉も聞いたことないし、病院やクリニックでどのような業務フローがあるかもわかっていない状態でしたが、必要な知識が効率よく学べるようにチェックリスト形式になっていたのでスムーズにキャッチアップできたと思います。
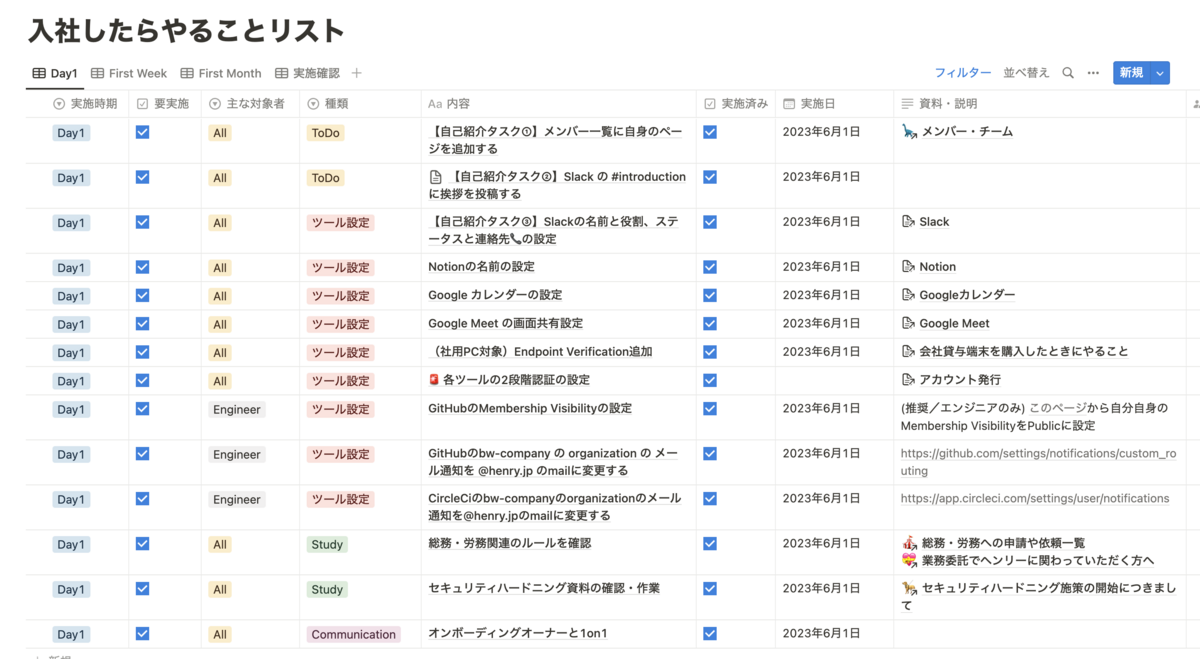
入社初日の TODO リスト
また、実務でもこれまでに発生した障害や不具合の対応などをまとめて開発に及ぼした影響などが判別しやすい指標を考えるというタスクを渡されて、開発の進め方や Henry の大まかなシステム構成などを俯瞰して眺めることができました。とくに不慣れな医療という現場でどのようにシステムが使われているかを座学で学んだ医療ドメインの知識と照らし合わせることができたのでコスパが良いキャッチアップタスクだったなと思っています。
これから何をするのか
前述のとおり Henry はこれからも成長を続けていくプロダクトですが、SRE 的な視点だとまだまだ未整備なところがあります。当面はサービスの開発と安定性の維持にバランスよく、かつ、最大の速度を出せるように SRE 的な知見の導入が主なミッションになっていくのかなと思っています。
上記の直接 Story に書いていくやり方は、さすがに古典的すぎるので、せめてファイルからインポートできるようにしたいです。というよりファイルからインポートできないと、プレビューとしての意義を果たせません。察しの良い方はすでにお分かりの通り、この辺りから Webpack のローダーをカスタマイズしていきます。
// macroModuleobject InferCodecs {
inline def gen[A]: Both[A] = {
summonFrom[Both[A]] {
case given Both[A] => implicitly[Both[A]]
case _: Mirror.ProductOf[A] => InferCodecs.derivedCodec[A]
case _ => error("Cannot inferred.")
}
}
inline def derivedCodec[A](using inline A: Mirror.ProductOf[A]): Both[A] =
new Both[A] {
override def write(value: A): Json = Writes.inferWrite[A].write(value)
override def read(value: Json): A = Reads.inferRead[A].read(value)
}
trait ProductProjection {
transparent inline def inferLabels[T <: Tuple]: List[String] = foldElementLabels[T]
transparent inline def foldElementLabels[T <: Tuple]: List[String] =
inline erasedValue[T] match {
case _: EmptyTuple =>
Nil
case _: (t *: ts) =>
constValue[t].asInstanceOf[String] :: foldElementLabels[ts]
}
}
object Reads extends ProductProjection {
inline def inferRead[A]: Read[A] = {
summonFrom[Read[A]] {
case x: Read[A] => x
case _: Mirror.ProductOf[A] => Reads.derivedRead[A]
case _ => error("Cannot inferred")
}
}
transparent inline def derivedRead[A](using A: Mirror.ProductOf[A]): Read[A] =
new Read[A] {
private[this] val elemLabels = inferLabels[A.MirroredElemLabels]
private[this] val elemReads: List[Read[_]] =
inferReads[A.MirroredElemTypes]
private[this] val elemSignature = elemLabels.zip(elemReads).zipWithIndex
private[this] val elemCount = elemSignature.size
override def read(value: Json): A = {
val buffer = newArray[Any](elemCount)
elemSignature.foreach { case ((label, read), i) =>
buffer(i) = {
read.read(value.nameOf(label))
}
}
A.fromProduct(
new Product {
override def canEqual(that: Any): Boolean = trueoverride def productArity: Int = elemCount
override def productElement(n: Int): Any =
buffer(n)
}
)
}
}
private inline def inferReads[T <: Tuple]: List[Read[_]] = foldReads[T]
private inline def foldReads[T <: Tuple]: List[Read[_]] =
inline erasedValue[T] match {
case _: EmptyTuple =>
Nil
case _: (t *: ts) =>
inferRead[t] :: foldReads[ts]
}
}
object Writes extends ProductProjection {
inline def inferWrite[A]: Write[A] = {
summonFrom[Write[A]] {
case x: Write[A] => x
case _: Mirror.ProductOf[A] => Writes.derivedWrite[A]
case _ => error("Cannot inferred")
}
}
inline def derivedWrite[A](using A: Mirror.ProductOf[A]): Write[A] =
new Write[A] {
private[this] val elemLabels = inferLabels[A.MirroredElemLabels]
private[this] val elemDecoders: List[Write[_]] =
inferWrites[A.MirroredElemTypes]
private[this] val elemSignature = elemLabels.zip(elemDecoders).zipWithIndex
private[this] val elemCount = elemSignature.size
override def write(t: A): Json = {
val entries = t.asInstanceOf[Product].productIterator.toArray
JsonObject(
(0 until elemCount).map { i =>
JsonString(elemLabels(i)) -> elemDecoders(i).asInstanceOf[Write[Any]].write(entries(i))
}.toMap
)
}
}
private inline def inferWrites[T <: Tuple]: List[Write[_]] = foldWrites[T]
private inline def foldWrites[T <: Tuple]: List[Write[_]] =
inline erasedValue[T] match {
case _: EmptyTuple =>
Nil
case _: (t *: ts) =>
inferWrite[t] :: foldWrites[ts]
}
}
}
複雑に見えますが、順に見ていきます。
InferCodecs.gen
inline def gen[A]: Both[A] = {
summonFrom[Both[A]] {
case given Both[A] => implicitly[Both[A]]
case _: Mirror.ProductOf[A] => InferCodecs.derivedCodec[A]
case _ => error("Cannot inferred.")
}
}
summonFrom というのはcompiletime APIで、scala2における implicitly[T] に近いものです。
パターンマッチによって、 given Both[A] がimplicit scopeに見つかればそれを返して終わります。
case _: Mirror.ProductOf[A] もpackageこそ変わっていますが馴染み深いのではないでしょうか?要するにケースクラスであり、メンバの型情報が導出できれば、という分岐で、
given Both[A] は見つからないけど、型情報導出できそうなのでReadとWriteをそれぞれ導出するぜ!という処理です。
Reads.inferReads
inline def inferRead[A]: Read[A] = {
summonFrom[Read[A]] {
case x: Read[A] => x
case _: Mirror.ProductOf[A] => Reads.derivedRead[A]
case _ => error("Cannot inferred")
}
}