株式会社ヘンリーでオブザーバビリティを担当しているsumirenです。
先日のHoneycombでスパンを削減する - 株式会社ヘンリー エンジニアブログ という記事で、スパン削減にはトレースカットとトレース横断の2つのアプローチがある話をしたうえで、トレース横断での削減について紹介しました。 この記事ではトレースカットでの削減についてヘンリーでの事例を紹介します。
スパン削減の戦略(再掲)
前の記事でも紹介したとおり、スパン削減には大きく2つの方向性があります。(アプリケーションを直す以外)
- トレースカットでのアプローチ
- トレースカットでサンプリングする
- 例:正常なトレースは1%だけサンプルする、無料ユーザーのトレースは1%だけサンプルするなど
- トレース横断的なアプローチ
- スパン種類ごとにドロップの条件をつける
- 例:SET TRANSACTIONのスパンは正常かつ高速ならドロップする
この記事で議論したいのは前者のアプローチです。紹介したいのは前者のアプローチで、便宜上トレースサンプリングと呼ぶことにします。 このアプローチにおいては、トレースをドロップすると判断したとき、含まれるスパンが基本的には全てドロップされます。
主要なトレースサンプリングの戦略とトレードオフ
一般に普及している2つのトレースサンプリングについて紹介します。
1. 確率サンプリング
(狭義の)確率サンプリングでは、事前に決めたパーセンテージ等で、トレースに対して無作為にサンプリングするかドロップするかを決めます。
魅力
この方法は導入が容易である点が魅力です。サンプリングレートを環境変数等で固定する場合は、スパン量の予算を実績値で割って計算するだけです。また、マイクロサービス側への設定も容易で、たとえばJVMなら直接Java Agentの設定値にotel.traces.sampler=parentbased_traceidratioという設定値が用意されていたりします。
無作為にサンプリングするため、Honeycombでスパンを集計したときに得られるメトリクスが大きく狂わない点も魅力です。
トレードオフ
この方法では確率のみでトレースをドロップしてしまうため、障害が発生したときなどにトレースを探すのが難しくなります。例えばヘンリーではSentryのIssueにトレースIDを付与しているので、Slackに通知が来た時点でそのトレースIDでHoneycombを見に行きたいです。エラー数が多くない場合、そもそも1つも当該エラーのトレースが取れていない可能性もあります。
2. エラー有無や応答速度ベースのサンプリング
エラーが発生したかや応答速度ベースでトレースをサンプリングする方法もあります。例えばエラーのときは必ずサンプルする等です。
魅力
この方法では、先ほど述べたようなインシデント発生時にSentryのIssueからトレースを見るといったオペレーションがスピーディにできます。また、障害とは非同期的なパフォーマンス分析会などでも、応答時間の遅いトレースをドロップしてしまっている懸念が小さくなります。
インシデント対応や異常への対処において必要なトレースが確実に取れているという信頼性が、この方法の主な魅力です。
トレードオフ
この方法は導入に一定のハードルがあります。ある程度処理が進んだ後でサンプリング有無を決める必要があるため、OpenTelemetry Collectorを多段構成にするなどしてテイルサンプリングを行う必要があります。構築と運用の人的コストや認知負荷、インスタンス台数が増えることによるコスト増なども想定されます。
一般に理想の最終形とされがちなテイルサンプリングですが、Honeycombのような強力なスパン分析の機能を持つオブザーバビリティバックエンドにおいては、集計値が狂う懸念もあります。異常を含むトレースのスパンを多く集めることになるので、エラーレートやレイテンシの集計値が実態と乖離することが想像されます。
加えて、システムの振る舞いに関して、エラーでなければ異常ではないのか?と考えると、必ずしもそうとは言えません。例えばバグにより会計の金額が1円ずれてもシステム上はエラーであると判断できませんが、実際には異常です。医療会計の複雑性はヘンリーの技術戦略上重要なテーマであり、こうした異常はむしろヘンリーにおいてオブザーバビリティが最優先でカバーしたい部分です。
価値のあるトレースかどうかを分けるディメンションを探す
このように考えていくと、トレースサンプリングにおいて確率サンプリングという無作為のサンプリング以上に適したサンプリング戦略を見つけることは、「自社において、あるトレースの有用性と強く相関するディメンションはどれか?それは十分多くのスパンを削減できる相関関係になっているか?」という問いに答えることと同義と言えます。
ヘンリーにおいては、エラー有無というディメンションではトレースの有用性との相関性が弱かったということです。「エラーではなくても異常」がありえて、かつそれがサンプルされることの重みが大きいためです。
他にも、以下のようなディメンションでのサンプリングが思いつきます。特にルートスパン等を生成する時点でわかる属性であればヘッドサンプリングも可能です。
- テナントIDベースでのサンプリング(大口顧客を高く重みをつける)
- 契約プランベースでのサンプリング(有料プランは重みをつける)
- 地域ベースでのサンプリング(注力市場ほど高く重みをつける)
- リリーストグルベースでのサンプリング(限定公開対象は高く重みをつける)
- エンドポイントベースでのサンプリング(新機能やリスクの高い機能は高く重みをつける)
- etc.
エンドポイントカットのトレースサンプリングという提案
こうしたことを踏まえて様々なディメンションを検討した結果、ヘンリーではエンドポイントベースでサンプリングを行うようにしました。
トレースの有用性との相関性
ヘンリーにおいては、GraphQLオペレーションの種類がトレースの有用性と大きく相関すると判断しました。医療会計に絡む部分は100%サンプルしたいためです。
それ以外にも、List系のQueryオペレーションなど、引数が少ないものは障害リスク等も低い傾向にあります。逆に、Mutation系は引数も多くステートフルであるため、障害リスクが高くサンプリングしておきたいです。
削減できるスパン量
削減できるスパン量からもこの相関性は都合が良いものでした。前回の記事で書いたとおり、Top5のオペレーションだけで全体の30%のスパンを占めていました。そして、これらは1つを除き全てQueryオペレーションでした。
それに加え、Top5以下もスパン消費が多いものはほとんどがQuery系であったため、たくさん生成されている上に有用性の低いスパンを削れると言えます。
トレードオフ
N+1やキャッシュ不足によりQuery系が大量スパンを生成している状態というのは、マシンリソースの無駄遣いをそのまま可視化できている状態とも言えます。これをドロップすれば、パフォーマンス改善余地を全体感を持って見ることが難しくなると言えます。
そのうえで、ヘンリーにおいては、パフォーマンスよりも振る舞いにフォーカスしてオブザーバビリティに取り組むほうが技術戦略として適切であると判断しました。医療会計の振る舞いに対するトレーサビリティが最も重要だからです。
加えて、新機能開発にあたり「設計が悪いとトレースが使えなくなる」といったプレッシャーがプロダクトチームにあることで、長期的にパフォーマンスの高いソフトウェアを作るカルチャーにつながる側面もあると考えています。ドロップする既存のGraphQLオペレーションについても、ルートスパンだけ残すことで最低限呼び出し回数やレイテンシの異常に気づき、サンプリング復活につなげる機会を残すことはできます。
実装例
要件
ルートスパンは残すようにし、ルートスパンが特定GraphQLオペレーションなら以下を全て削る、という仕様にしました。
これにより、集計時にis_rootで絞ればドロップ対象のオペレーションでも全体レイテンシや呼び出し回数などが出せる状態を維持できました。加えて、ルートスパンには手動計装によりテナントIDやフィーチャーフラグの状態、エラーメッセージなどもすべて入っており、こうした集計も十分トラブルシュートの役に立ちます。
設計
全体像
スパン生成時点でGraphQLオペレーションの種類はわかるため、アプリケーション上でカスタムのSamplerを作成するヘッドサンプリングでの実現が可能です。
デフォルトのサンプリングロジックはParentBasedになっており、「親のサンプリング状況に従う」となります。ヘンリーではBFFをルートとして裏にマイクロサービスがいるため、以下のような修正になります。
- BFFのサンプラーはカスタムサンプラーを実装する
- マイクロサービスのサンプラーはAlwaysOnをやめてParentBasedにする
BFFのサンプラーの設計
ParentBasedSamplerはSamplerのコンポジションになっていて、以下のように5つのパターンに対してSamplerを定義することができます。
今回はParentBasedSamplerを使いつつ、そこに渡すSamplerを自前で実装します。
- ルートスパンを生成するときのサンプリングロジック(今回は必ずほしいので
AlwaysOnSamplerを渡す) - 子スパンを生成するときで親スパンがサンプルされている場合
- 親スパンが自サービス内で生成されている場合(今回はここでドロップ判断したいためカスタムサンプラーを書いて渡す)
- 親スパンが上流サービスで生成されている場合(今回はルートにあたりサービスなので関係なし)
- 子スパンを生成するときで親スパンがドロップされている場合
- 親スパンが自サービス内で生成されている場合(今回はルートは必ずサンプルするため孫スパンになる。当然いらないため
AlwaysOffSamplerを渡す) - 親スパンが上流サービスで生成されている場合(今回はルートにあたりサービスなので関係なし)
- 親スパンが自サービス内で生成されている場合(今回はルートは必ずサンプルするため孫スパンになる。当然いらないため
注意点
Context PropagationのPropagatorを自作している場合は、サンプリングフラグを正しく実装しないと下流マイクロサービス側のParentBasedの動きが狂うため注意ください。
カスタムサンプラーの実装例
TypeScriptでの実装例です。ParentBasedSamplerのlocalParentSampledに渡します。
export class GraphQLLocalParentSampler implements Sampler { private discardList: Set<string>; constructor(discardList: string[]) { this.discardList = new Set(discardList); } shouldSample(parentContext: Context | undefined): SamplingResult { const span = parentContext ? trace.getSpan(parentContext) : undefined; // TODO: これ以外にattrのgetterを得る方法見つからず。暇なときになおしてくれる人を募集してます const readableSpan = span as unknown as ReadableSpan; const operationName = readableSpan?.attributes?.["graphql.operation.name"] as string | undefined; if (typeof operationName !== "string") { return { decision: SamplingDecision.RECORD_AND_SAMPLED }; } // 親スパンが当該operationならドロップする。このあとはこのParentBasedSamplerに渡しているlocalParentNotSampledが動く想定 if (this.discardList.has(operationName)) { return { decision: SamplingDecision.NOT_RECORD }; } return { decision: SamplingDecision.RECORD_AND_SAMPLED }; } }
OpenTelemetryにおいてローカル内で値を取り回すベストプラクティスがなかなか見つからず、OpenTelemetryのためだけにアプリケーションのリクエストコンテキストにステートを追加したくなかったため、このように実装しています。
一度サンプル側に入ればあとはlocalParentNotSampledが動くので、1リクエストあたりほぼ1回しか来ないため、性能面の懸念もないと判断し、これで良しとしました。
ベストプラクティスをご存じの方がいましたら、ぜひ発信いただけると幸いです。
結果
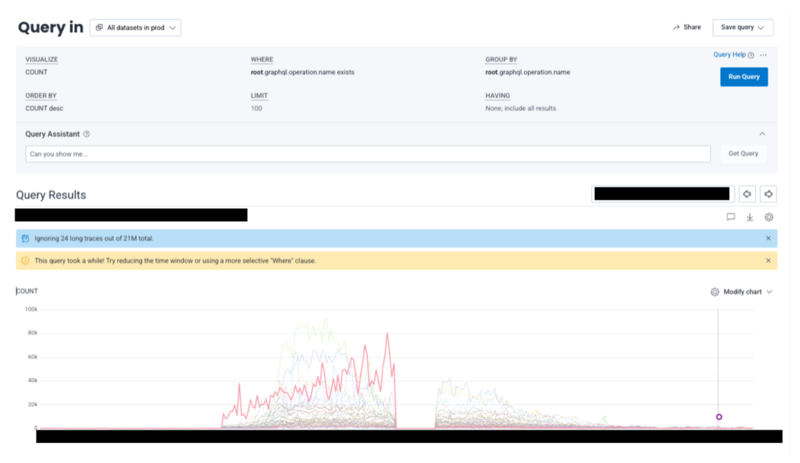
特定のエンドポイントだけ大きくスパン数を削減することができました(一瞬スパン数がゼロになっていますが、こちらは別件です)。
まとめ
自社の向き合っている市場やプロダクト特性次第で最適なサンプリング戦略は変わると筆者は考えています。必ずしもテイルサンプリングが必要とは限りません。
そのうえで、エンドポイントカットのヘッドサンプリングは、エラーや応答時間ベースのテイルサンプリングと同じくらい汎用性が高く、多くの組織にとって優れた戦略になりうるのではないでしょうか。
ぜひ自社に最適なサンプリング戦略をチームで議論してみてください。