ヘンリーでSRE / SDETをしているsumirenです。
この記事は株式会社ヘンリーAdvent Calendar 2023の9日目の記事です。昨日は id:nabeop の カジュアルな社内勉強会 : ギベンの紹介 という記事でした。
背景
ヘンリーでは分散トレーシングにOpenTelemetryを用いています。元々、ログはCloud Runの標準出力をCloud Loggingが拾ってくれるものを見ており、メトリクスもCloud Runがマネージドで取得してくれるものを見ていました。しかし、オブザーバビリティを高め、また民主化するためには、トレースを起点にメトリクスやログなど全てのシグナルを追えるべきだと考え、OpenTelemetryを導入しました。
ローカルでいくつかのマイクロサービスとOpenTelemetry Collectorを立ち上げ、Jaegerで分散トレースを追えるようにするまでは簡単でした。長かったのは、計装の入ったサービスをクラウドにデプロイしてから、実際に使えるようになるまでです。
この記事では、そうしたヘンリーでの導入事例から、クラウドへのOpenTelemetry導入のハマりどころを2つ抜き出して解説します。実際に皆様が全く同じ問題にぶつかることは考えづらいですが、問題の理解を通してOpenTelemetryへの理解度が高まることを目指しています。
この記事は導入とアプリケーションレイヤにフォーカスします。運用中の問題やネットワークレイヤの問題は取り上げません。
1. クラウドプラットフォームがトレースに干渉する
事象
最も大きな問題は、「クラウド上でなぜかトレースが切れる」というものでした。
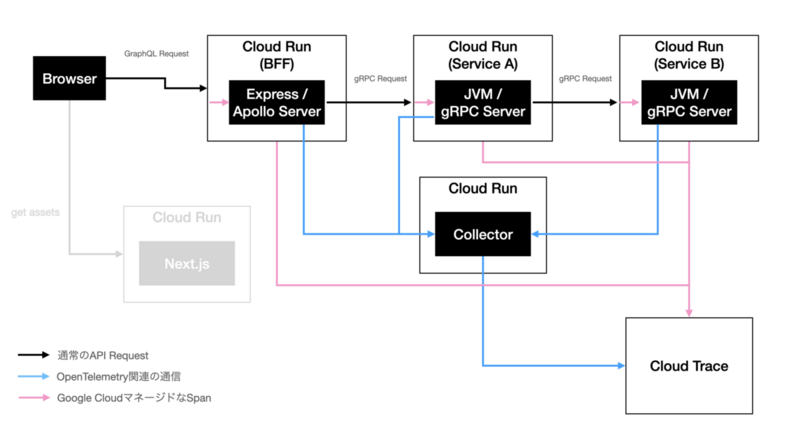
ヘンリーではGoogle Cloudを採用しているため、トレースバックエンドとしてはCloud Traceを検討していました。以下がシステムの構成です。
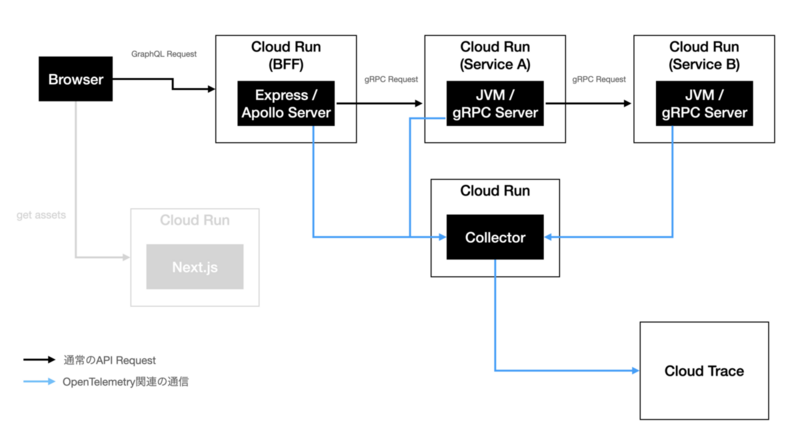
フロントエンドからのGraphQLリクエストをBFFで受け付け、gRPCを提供するバックエンドのマイクロサービスに対して解決しています(図中黒い線)。その過程で、OpenTelemetryの自動計装により各サーバーからOpenTelemetry Collectorへのテレメトリーデータが流れ、Cloud Traceに集約されています(図中青い線)。なお、フロントエンドサーバーは今回あまり関係がないためグレーアウトしています。
こちらをローカルで動かしたときのトレースのイメージは以下のとおりです。うまく動いており、BFFの処理の一部でマイクロサービスを2回呼び出しているといったことがわかります。
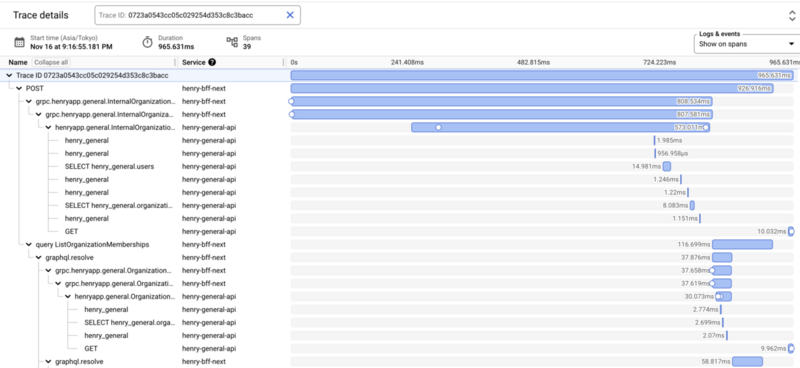
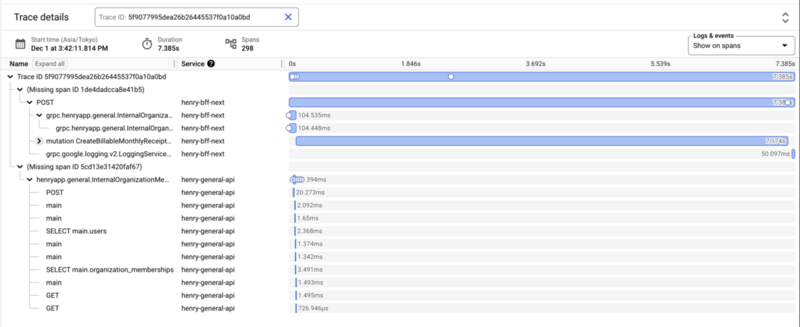
一方、ソフトウェアとOpenTelemetry CollectorをCloud Runにデプロイすると、当初は以下のようなトレースになってしまっていました。BFFの処理とマイクロサービスの処理の関係性が現れておらず、トレースに対して2本のツリーがあるように見えます。
原因
Cloud RunがOpenTelemetryに干渉することが原因でした。
前提知識として、OpenTelemetryでは、個別のサービスがOpenTelemetry Collectorやオブザーバビリティバックエンドにトレースを中心としたシグナルをそれぞれ独自に送ります。その際、サービス間で自分のスパンがどのスパンの子になるべきか知るために、サービス間の呼び出しにデフォルトではtraceparentヘッダというHTTPヘッダを使います。この機能をContext Propagationと言います。もしContext Propagationについて詳しくなければ、手前味噌ですがこちらの記事も参照してみてください。
OpenTelemetry 分散トレーシングのシステムアーキテクチャ
Cloud Runは、このtraceparentヘッダを見つけると、独自のスパンを発行し、traceparentヘッダを書き換えて自身が乗せているアプリケーションに対してリクエストをプロキシします。この独自のスパンはCloud Traceに送信されます。先程のシステム構成について、この動きを書き加えたものが以下の図解になります(図中ピンクの線)。私たちの預かりしらぬところでCloud Runがスパンを割り込ませ、Cloud Traceに連携していることが分かるでしょうか。
問題は、Cloud Runは自身が生成したスパンをデフォルトではほとんどサンプリングで間引いてしまいCloud Traceに連携しないということです。
OpenTelemetryのデフォルトのサンプリングロジックでは、親スパンがある場合には親スパンのサンプル有無に従います。親がサンプルしたかどうかはtraceparentヘッダのtrace flagsというカラムからわかります。しかし、Cloud Runはtraceparentヘッダに干渉するにも関わらず、Parentbasedなサンプリングロジックになっていません。つまり、BFFやマイクロサービスにAlwaysOnのサンプリング設定をしても、Cloud Runは独自の仕様でCloud Traceに独自に生成したスパンを連携するかどうかを勝手に決めてしまうということです。
トレースは子スパンが親スパンのIDを持つことで成り立っているツリー構造です。1つでも間のノードが抜けてしまえば、その部分はツリーが分断してしまい、オブザーバビリティバックエンド目線は独立した2つのツリーに見えてしまいます。こうして、上記のような事象が発生したというわけです。
この状況を脱するには、Cloud RunにOpenTelemetryへの干渉をやめさせるか、Cloud Runに必ずスパンを生成させるか、全てのトレースを保存することを諦めれば良いということになります。
学び
ここで伝えたかったことは、Context PropagationがHTTPヘッダを用いたもので、かつtraceparentのように標準化されているために、PaaSやIaaSがインターセプトする余地があるということです。
トレースがいくつかのツリーに細切れになってしまったり、一部のスパンしか可視化されないとしたら、こうしたクラウドによるおせっかいな干渉を疑うと良いかも知れません。
加えて、この事例を通じて、Context Propagationやサンプリングに対する皆様の理解が深まっていましたら幸いです。
余談
この記事の趣旨はあくまでクラウド一般でのOpenTelemetry導入のハマりどころです。そのため以下は余談ですが、ヘンリーではこの問題は完全には解消していません。
Cloud Traceのドキュメントには、フロントエンドからのリクエストに特定のHTTPヘッダを付与することでトレースを強制させることが可能とあるのですが、ヘンリーでは度々トレースされない事象を確認しており、現在サポートとやりとりをしています。
そして、仮にCloud Runにトレースを強制させることに成功したり、Cloud RunがParentbasedなサンプリングロジックを実装することで、スパンが抜ける現象が解決しても、ベンダーロックインになっているという問題が残ります。例えばDatadogなどに移行したくなったときには、結局Cloud Runが生成したスパンはCloud Traceにしか伝わっておらず、Datadog目線はスパンが抜けてしまうという問題が発生するからです。
これを防ぐためには、皮肉なことにOpenTelemetryをやめてDatadog Agentのような独自エージェントを使うのが一番手っ取り早いかもしれません。他には、Cloud Runの知らないPropagatorを使うという手段も考えられます。
個人的には、Cloud Runの設定でOpenTelemetryへの干渉を無効化できると一番嬉しいです。
2. シグナルを全てOpenTelemetryで扱うとクラウドプラットフォームの恩恵を受けづらい場合がある
事象
当初は、トレースと併せてログやメトリクスもOpenTelemetryベースで取り扱うことを考えていました。トレースとの紐づけが自動的に行われるからです。
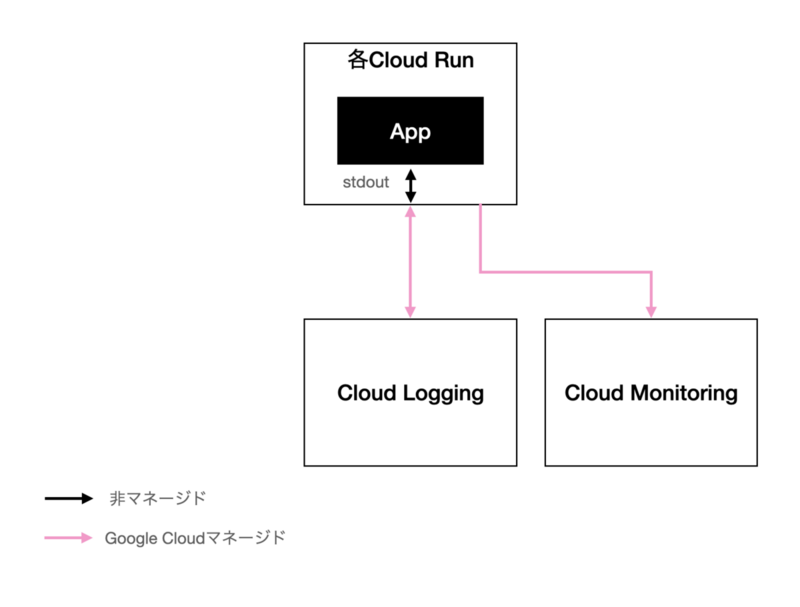
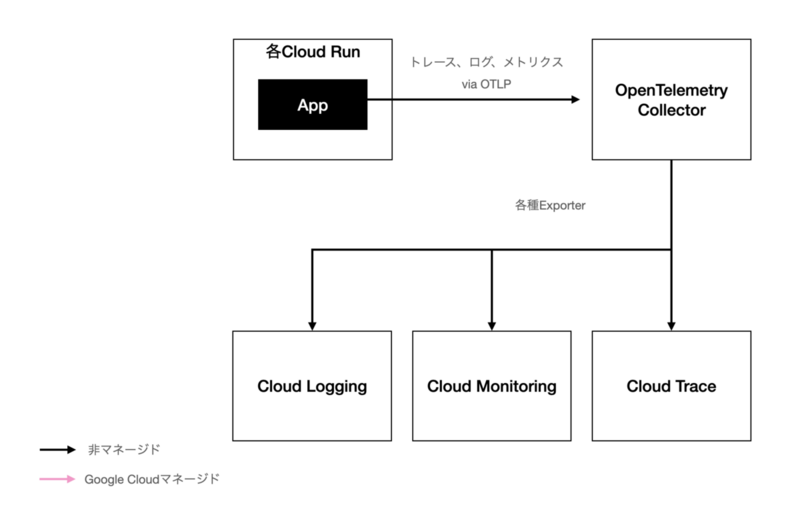
以下はOpenTelemetry導入前の図解です。実際には構造化ログに対するtraceIdの採番はできていましたが、トレースやメトリクスは使っていなかったため導入前と表現しています。ログに関しては標準出力に出す部分だけで自身でコントロールしており、メトリクスにいたってはフルマネージドでした。
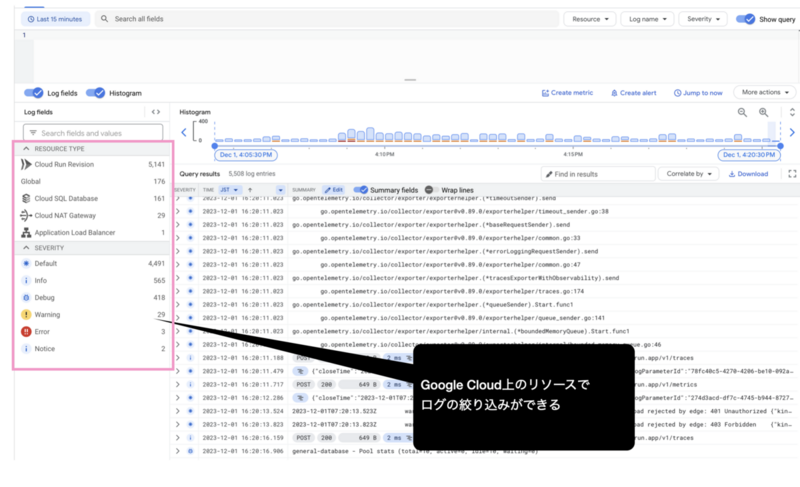
今回、トレース以外にログやメトリクスもOpenTelemetryベースでOpenTelemetry Collector(またはオブザーバビリティバックエンド)に送信する検証をした際に、Cloud LoggingとCloud Runの標準の連携が効かなくなるという事象が発生しました。以下はある検証環境におけるCloud Loggingの画面なのですが、図解のとおり、Cloud Runなどの他のGoogle Cloudのサービスと連携してログを絞り込む機能があります。OpenTelemetryベースでログを送ると、この機能が使えなくなってしまいました。
原因
このときのシステム構成の図解は次のとおりでした。Google Cloudマネージドで実現される部分はなくなっており、全てがセルフコントロールとなっています。
ご想像のとおり、事象の原因は、Google Cloudマネージドな連携ではなくなったことです。当初はCloud LoggingはCloud Runとのマネージドな連携によりログの出処がCloud Runであることが分かっており、Google Cloudの強みである機能間のシナジーを活かせていました。アプリからOpenTelemetry Collectorを経由してログが送りつけられるようになったことで、それが分からなくなってしまったということです。
実際には、Cloud Loggingは構造化ログに含まれているメタデータを見ることでGoogle Cloud上のどのリソースで発生したログなのかを判断しているようです。そのため、本来Cloud Runがやっているであろう構造化ログへの属性の付与をアプリケーション上で行えば、こうした機能を維持できるようです。実際、そうした処理を自動で行うためのエージェントもGoogle Cloudから出ているようです(どちらもヘンリーでは検証していません)。
しかし、stdoutに書き出すだけの標準の連携に比べると、構造化ログをいじったりエージェントを追加するのは少々手間でした。また、今までとログの出方がやや変わってしまう不安もありました。そうしたことから、ヘンリーではログだけ今までどおりstdoutによるCloud Loggingへの連携に倒しました。図解にすると、次のような構成です。
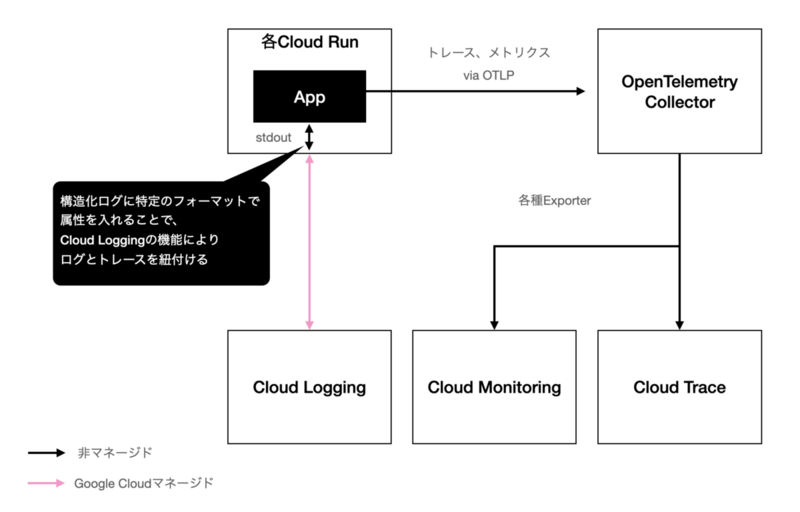
オブザーバビリティにおいて重要なのは、ログやメトリクスをトレースと紐付けることです。Cloud Loggingの場合、上記図解のような構成でも一工夫加えることでログとトレース(スパン)を紐付けることができます。構造化ログにtraceとspanIdという属性を生やすだけです。アプリケーション上でOpenTelemetryのSDKを用いることで、現在のリクエストのコンテキストにおけるtraceとspanIdを取得し、構造化ログに埋め込みます。
学び
ここで伝えたかったことは、一口にOpenTelemetryを採用するといっても、クラウドの技術スタックに応じて各シグナルの最適な扱い方が変わりうるということです。
ローカルで検証しているうちは、トレースもログもメトリクスも全てotlpでOpenTelemetry Collectorに送って、そこからJaegerなどの各種オブザーバビリティバックエンドに送ればいいような気持ちになります。しかし実際には、Cloud Logging等のクラウドプラットフォームに付随するオブザーバビリティツールの標準の連携を活かすほうが速かったり、従来のログやメトリクスの出方を大きく変えたくない場合などが出てくると思います。
そのため、クラウド上でのシステム構成のイメージを早めにつけた状態で、検証の計画などを立てていけると良いと思います。
まとめ
OpenTelemetryの活用方法は実際のところクラウドに大きく依存します。PaaSがOpenTelemetryに干渉したり、ツール間のシナジーを活かしつつOpenTelemetryのパワーを最大限発揮したくなったりします。
こうしたことを踏まえ、クラウドドリブンでOpenTelemetryの導入を検討・検証していくとよいのではないでしょうか。そして、トラブルにぶつかった際にはこの記事の内容を思い出していただけると、何かの役に立つかも知れません。
ヘンリーでも、今度はDatadogの採用を検討していますが、この記事で紹介した経験を踏まえて、トレースだけでなくログやメトリクスのDatadogへの流し方や紐づけ方について最初から仮説を立ててPoCを進めています。
ヘンリーではSREやQAエンジニアなど各種職員を募集しています。話だけでも聞いてみようかなと思っていただけるようでしたら、ぜひご連絡ください。お話しましょう。