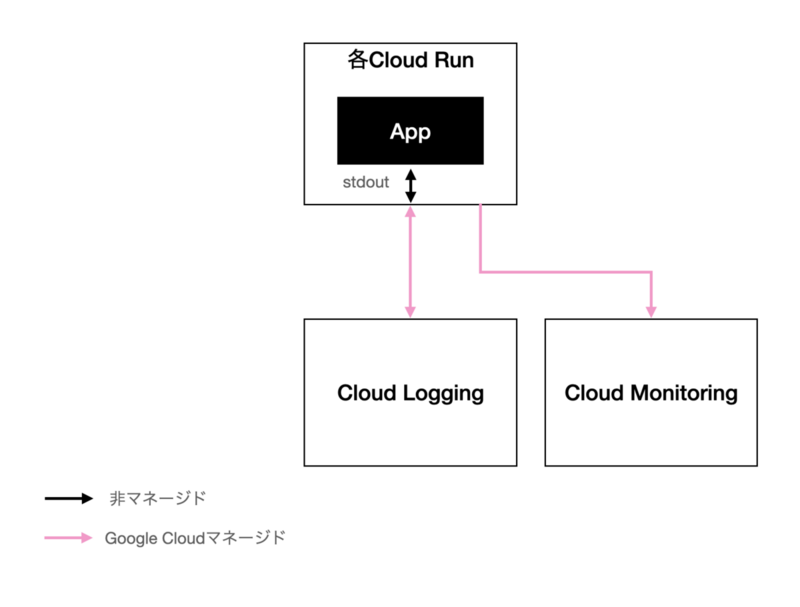
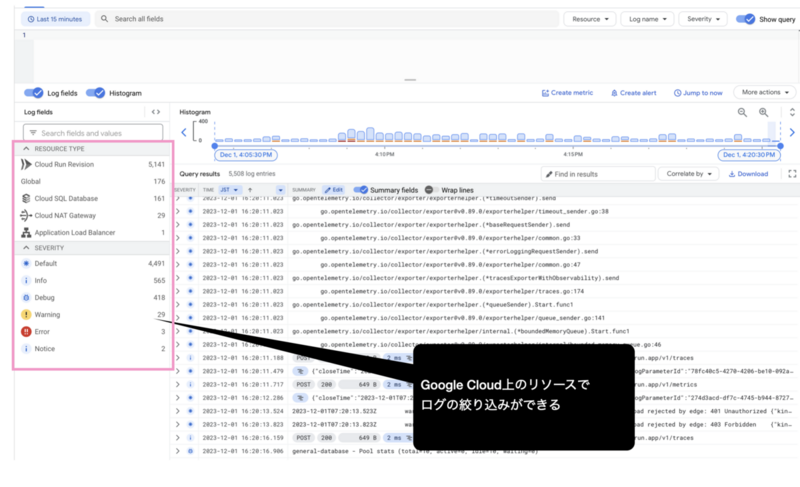
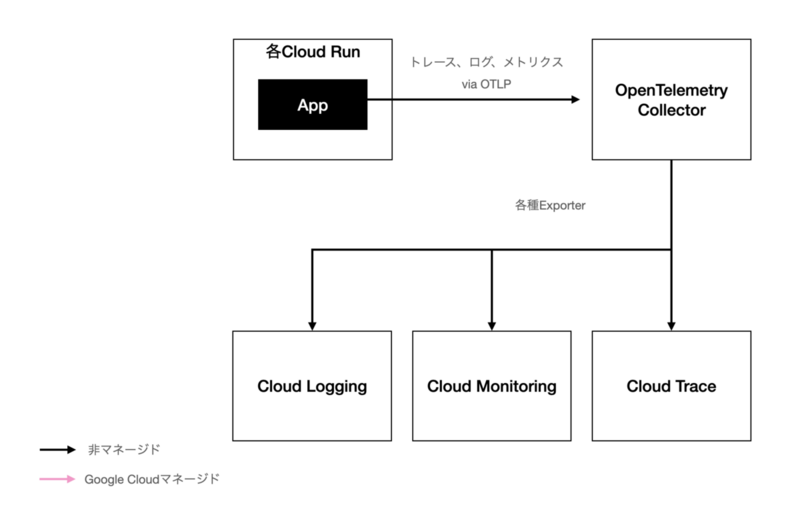
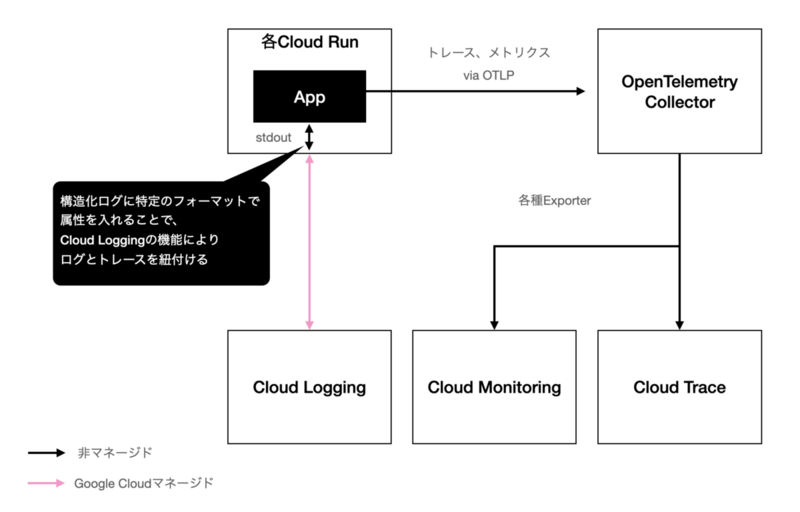
【この記事は株式会社ヘンリーAdvent Calendar 2023の24日目の記事です。昨日は 嶺野さんによるヘルステックエンジニアのキャリアという話でした。】
こんにちは!2023年10月にヘンリーに入社した山口(@tyamaguc07)です。 エンジニアとして、主にHenryのレセコン(医療費・診療報酬)の開発に携わっています。
ドメインキャッチアップの重要さ、難しさ、そして楽しさ
ヘンリーで医療ドメインの理解は欠かすことができないものです。しかし、医療ドメインは情報量が多いだけでなく、読み解く必要性や、深く理解する必要性がある世界です ドメインキャッチアップの重要さや、難しさ(そして楽しさ!!)は @agatan の記事でも触れられています。
電子カルテ・医事会計システムとは、病院における業務基幹システムです。 ご存知の通り、病院にはさまざまな職種(医師、看護師、医療事務、検査技師、etc...)の方がいらっしゃいます。 専門職の方々が、互いに情報をやりとりしながらご自身の専門業務を遂行しています。 それぞれの業務は専門性の高い業務であり、単体で見ても複雑で難易度の高い一つのドメインです。 継続的に、より高い価値を届け続けるためのソフトウェアを開発するためには、そもそも開発対象を深く理解し、それをモデリングする・改善し続けることに心血を注ぐ必要があります。
Henry の開発はなにが楽しい?ソフトウェアエンジニアにとっての魅力と挑戦をご紹介します! - 株式会社ヘンリー エンジニアブログ
診療報酬制度では、保険医療の価格や、ある保険医療を実施するために医療機関が満たしているべき条件、提出すべき書類などが定められています。 ものによっては、継続的に統計データを提出する必要があったり、入院中の患者に対して日々記録を取っておく必要があったりします。 ルールの数も多いのですが、個々のルールについて読み解くのも非常に難しく、これをモデリングする作業には、パズルや謎解き的な面白さがあります。 きれいにモデリングできたときには、ものすごく気持ちよくなれます。
Henry の開発はなにが楽しい?ソフトウェアエンジニアにとっての魅力と挑戦をご紹介します! - 株式会社ヘンリー エンジニアブログ
※ 太字は私による強調
入社して3ヶ月が経ち、実体験を通じて、これらの難しさを乗り越えることの楽しさ、そして乗り越えた先の楽しさがあるのは間違いないと考えています。
しかし、同時にもっと効率的に向き合う方法はないのだろうかとも考えています。
組織としても、来年の100人採用に向けて医療ドメインの理解を効率的に進める方法が仕組みかされていることは重要であると考えています。
そんな中、今年読んだ「プログラマー脳 ~優れたプログラマーになるための認知科学に基づくアプローチ 」(以下、本書)の学びが医療ドメインの理解に応用できるのではないかと考えました。
本書は、認知科学に基づいてプログラミング時に発生する認知負荷をどのように軽減できるかを解説しており、非常に学びの多い一冊でした。
認知負荷は、プログラミングを行う際に限らず他の多くの状況でも発生する現象です。
本書で示されている考え方を転用し、医療ドメインの理解における認知負荷の軽減に応用してみようと思います。
慣れない文章を読む際に発生する問題に向き合う
本書では、まず、慣れないコードを読む際に発生する混乱は長期記憶、短期記憶、ワーキングメモリそれぞれに問題が発生すること、どのように対策できるのか述べられています。
この、慣れないコードを読むプロセスは、厚生労働省から公表される資料や診療報酬制度の文書を読むプロセスと類似していると考え、問題の理解と対策が、転用できるのではないかと考えました。
長期記憶の問題
未知の用語や略語はそれが何であるかを理解できないため、混乱の発生要因となり、理解を進める際の障壁となります。
対応策: 知っている単語や概念を増やす
対象ドメインにおいて知っていることを増やすかというシンプルな対応策です。
ヘンリーでは継続的にメンテナンスされている用語集ががあるので、それを学習に利用することが可能だと考えています。
本書では、素早く学ぶためにフラッシュカードを使うことが提案されています。
具体的なアクション
- 用語集をフラッシュカード化し学習に利用する
短期記憶の問題
資料の一文に出てくる単語や概念の数が多いので、短期記憶にとどめておくことができず理解を妨げる傾向があります。
たとえば、以下のような文章を見たときには面食らいました。
Ⅱの規定にかかわらず、薬事法等の一部を改正する法律(平成 25 年法律第 84 号)第1条の規定 による改正前の薬事法(昭和 35 年法律第 145 号)第 14 条第1項又は医薬品、医療機器等の品質、有 効性及び安全性の確保等に関する法律(昭和 35 年法律第 145 号)第 23 条の2の5第1項の規定による承認を受け、次の表の左欄の承認番号を付与された同欄に掲げる特定保険医療材料の同表の中欄に掲げる期間における材料価格は、それぞれ同表の右欄に掲げる材料価格とする。
対応策: チャンキングをできるようになる
チャンキングとは物事を覚えるときに複数の情報を一つにまとめ、覚えるべきことの数を減らして短期記憶にとどめやすくすることです。
先程の文章であれば、以下のようにチャンキングできるようになると考えています。
- 「Ⅱ」の規定にかかわらず、 - 薬事法等の一部を改正する法律によって - 次の表の材料価格とする。
プログラミングの場合は、私達でチャンキングしやすいようにコードを書くこと効率化を図れますが、医療ドメインの情報に関してはこの方法で効率化は図れません。
したがって、与えられた文章を如何にチャンキングできるようになるかが重要となります。
何を知っていればチャンキングができるようになるのでしょうか?
本書では、プログラミングに関する概念、データ構造、文法を知っていればいるほどコードを簡単にチャンク化できるようになると書かれています。
これを、医療ドメインのキャッチアップに転用すると以下の情報を知ることでチャンク化できるようになるのではないかと推測しています。
- 公表される文章のよくある構成
- 医療制度の背景にある考え方
- Henryを開発するにあたって必要な情報、あるいは不要な情報
いずれもオンボーディング時にざっくりと共有可能な情報です。
しかし、プログラミングと比べると明確な情報ではないため、チャンク化しながら文章を読む訓練もより必要であると考えています。
具体的なアクション
- チャンク化するために有効な情報をオンボーディングで共有する
- 公表される文章をチャンク化しながら読む訓練を行う
ワーキングメモリの問題
コードが複雑で把握する変数や状態が多いときに発生するもので、理解を妨げます。
医療ドメインにおいても同様に変数や状態が多い文章があるケースがあり、理解を妨げます。
さらに、自然言語ならではの問題として修飾されている対象が不明瞭であったり、文中で名言されていないがコンテキストから察する必要がある事象などがあり、これも理解を妨げます。
たとえば、ある公費のルールは以下のようなものです。
大阪の乳児医療は1日500円以上の場合は限度額500円までとなる(当月2日間は500円限度、それ以降は患者様請求額0円)
CodeGolfでもしたのかと思えるほど情報が削ぎ取られています。
対応策: リファクタリングする
本書では、リファクタリングがワーキングメモリの問題に効果的であることが述べられています。 医療ドメインの理解で発生する同様の問題においても、文章に対してリファクタリングが有効であるように考えられます。先のルールをリファクタリングしてみると以下のようになります。
1)ある月において1回目の外来受診日における患者の負担額は500円を上限となる。 これは、1回目の外来受診日に複数回外来を受診したとしても、その日に患者が負担する金額は500円までになることを意味する。 2)ある月において2回目の外来受診も同様である。 3)ある月において3回目以降の外来受診に関しては負担額は0円となる。
長くはなりましたが、ルールの内容が具体的になったと思います。
一方、コードのリファクタリングがそうであるように、リファクタリング前後でルールが変わっていないことを担保する必要があります。
ヘンリーではドメインエキスパートとの協業を前提としているため、ルールが変化していないことを確認することが可能です。
ドメインの理解を進めている最中は、そもそもリファクタリングすること自体が難しい可能性はあります。その場合は、ドメインエキスパートにリファクタリングしていただくことも選択肢にあがります。
具体的なアクション
実装に落とし込むような文章・ルールに関しては、リファクタリングを行う。あるいはドメインエキスパートにリファクタリングを依頼する。
次回?
本書では、他にもメンタルモデルが認知負荷に及ぼす影響であったり、意味波(semantic wave)を踏まえた学習プロセスのアンチパターンなども紹介されています。
これらを取り入れた方法も考えているので、整理できたタイミングでまた記事を書こうと思います。
ここまで読んでいただき、ありがとうございました!